BIGDATA PROJECTS
At TECHNOFIST we provide academic projects based on Bigdata with latest IEEE papers implementation. Below mentioned are the list and abstracts on Bigdata domain. For synopsis and IEEE papers please visit our head office and get registered
OUR COMPANY VALUES : Instead of Quality, commitment and success.
OUR CUSTOMERS are delighted with the business benefits of the Technofist software solutions.
IEEE BIG DATA/HADOOP BASED PROJECTS
TECHNOFIST provides BigData Hadoop based projects with latest IEEE concepts and training in Bangalore. We have 12 years experience in delivering BigData Hadoop based projects with machine learning and artificial intelligence based applications with JAVA coding. Below mentioned are few latest IEEE transactions on BigData Hadoop. Technofist is the best institute in Bangalore to carry out BigData Hadoop based projects with machine learning and Artificial intelligence for final year academic project purpose.
. Latest BigData Hadoop concepts for what is essential for final year engineering and Diploma students which includes Synopsis, Final report and PPT Presentations for each phase according to college format. Feel free to contact us for project ideas and abstracts.
Students of ECE, CSE , ISE , EEE and Telecommunication Engineering departments, willing to pursue final year project in stream of software projects using JAVA coding can download the project titles with abstracts below.
| TBD001 | |
| TBD002 | |
| TBD003 | |
| TBD004 | |
| TBD005 | |
| TBD006 | |
| TBD007 | |
| TBD008 | |
| TBD009 | |
| TBD010 | |
| TBD011 | |
| TBD012 | |
| TBD013 | |
| TBD014 |

CONTACT US
For IEEE paper and full ABSTRACT
+91 9008001602
technofist.projects@gmail.com
Technofist provides latest IEEE Bigdata Projects for final year engineering students in Bangalore | India, Bigdata Based Projects with latest concepts are available for final year ece / eee / cse / ise / telecom students , latest titles and abstracts based on Bigdata Projects for engineering Students, latest ieee based Bigdata project concepts, new ideas on Bigdata Projects, Bigdata Based Projects for CSE/ISE, Bigdata based Embedded Projects, Bigdata latest projects, final year IEEE Bigdata based project for be students, final year Bigdata projects, Bigdata training for final year students, real time Bigdata based projects, embedded IEEE projects on Bigdata, innovative projects on Bigdata with classes, lab practice and documentation support.
Bigdata based project institute in chikkamagaluru, bigdata based IEEE transaction based projects in Bangalore, bigdata projects in Bangalore near RT nagar, final year bigdata project centers in Hassan, final year bigdata project institute in Gadag, final year bigdata project institute in Uttara Karnataka, final year bigdata based project center in RT nagar, final year bigdata projects in Bangalore @ yelahanka, final year bigdata based projects in Bangalore @ Hebbal, Final year bigdata based projects in bangalore@ koramangla, final year bigdata based projects in Bangalore @ rajajinagar. IEEE based bigdata project institute in Bangalore, IEEE based bigdata project institute in chikkamangaluru, IEEE project institute in davangere, IEEE project institute in haveri, final year bigdata based projects in hebbal, final year bigdata based projects in k.r. puram, final year bigdata based projects in yelahanka, final year bigdata based projects in shimoga. Latest projects at Yelahanka, latest projects at hebbal, latest projects at vijayanagar, latest projects on bigdata system at rajajinagar, final year bigdata based projects at RT nagar, final year project institute in belgaum, project institute at kengeri, IEEE based project institute in jaynagar, IEEE based project institute in marathahalli, final year bigdata based project institute in electronic city. Final year bigdata based project institute in hesarghatta, final year bigdata based project institute in RR nagar. Final year based project institute in jalahalli, final year bigdata based project institute in banashankari, final year bigdata based project institute in mysore road, bigdata final year based project institute in bommanahalli.
ABOUT HADOOP
Hadoop is an open-source framework that allows to store and process big data in a distributed environment across clusters of computers using simple programming models. It is designed to scale up from single servers to thousands of machines, each offering local computation and storage.
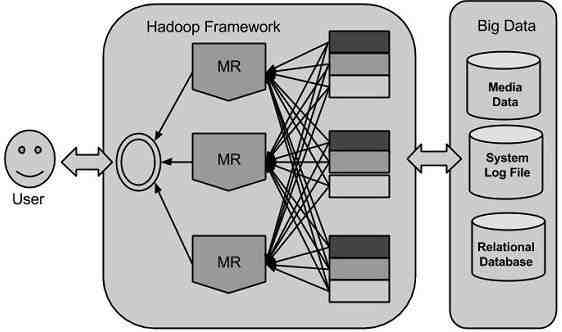
Hadoop framework includes following Modules:
- Hadoop MapReduce
- Hadoop Distributed File System (HDFS™)
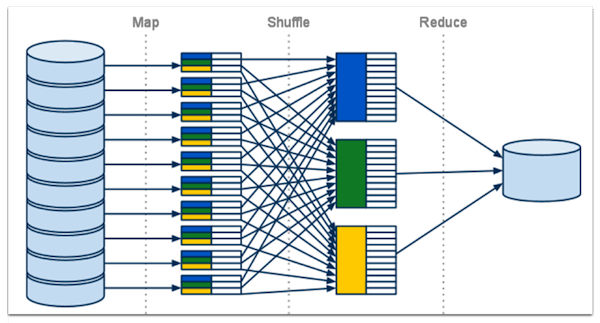
MapReduce
Hadoop MapReduce is a software framework for easily writing applications which process big amounts of data in-parallel on large clusters (thousands of nodes) of commodity hardware in a reliable, fault-tolerant manner.
The term MapReduce actually refers to the following two different tasks that Hadoop programs perform:
- The Map Task: This is the first task, which takes input data and converts it into a set of data, where individual elements are broken down into tuples (key/value pairs).
- The Reduce Task: This task takes the output from a map task as input and combines those data tuples into a smaller set of tuples. The reduce task is always performed after the map task.
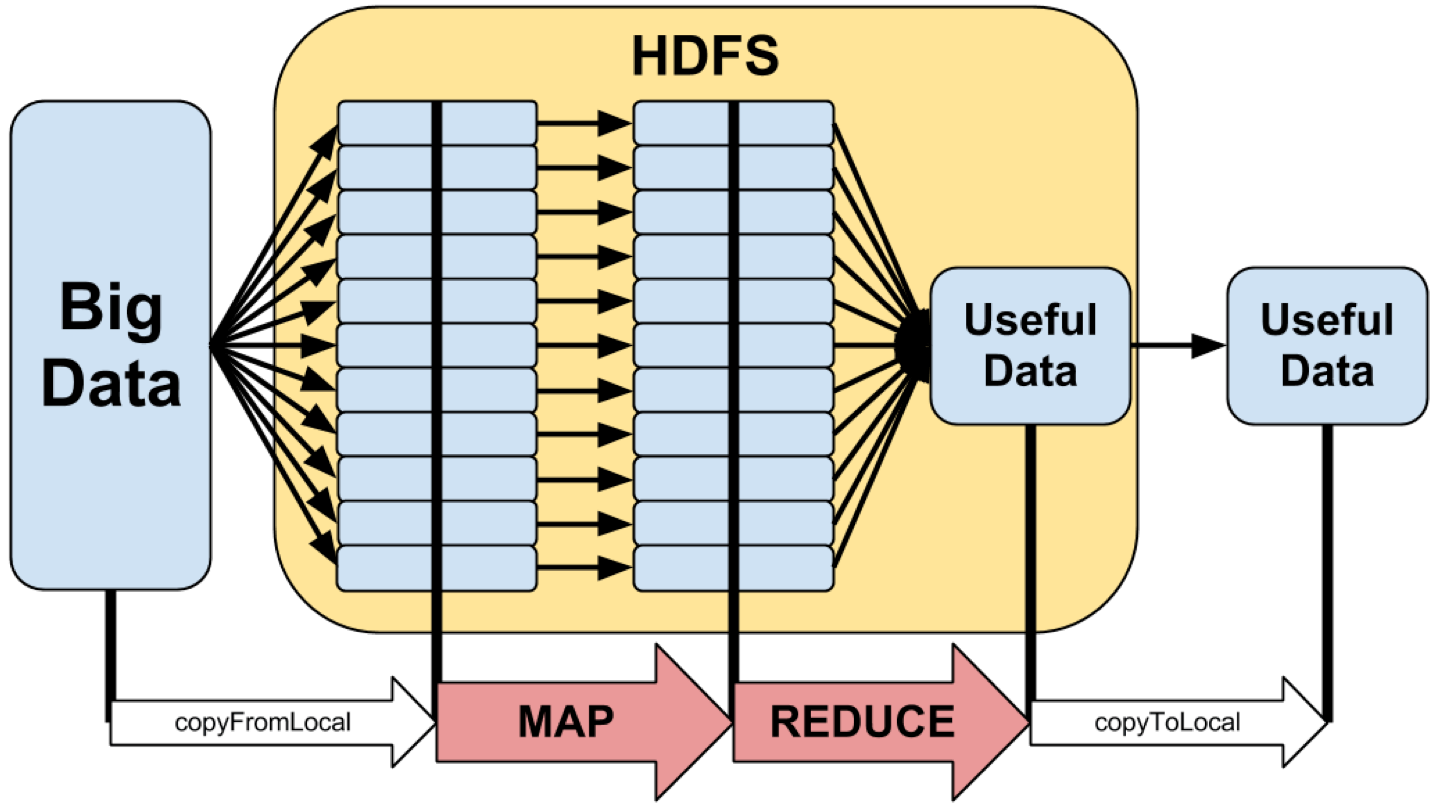
Hadoop Distributed File System (HDFS)
Hadoop File System was developed using distributed file system design. It is run on commodity hardware. Unlike other distributed systems, HDFS is highly fault tolerant and designed using low-cost hardware.HDFS holds very large amount of data and provides easier access. To store such huge data, the files are stored across multiple machines. These files are stored in redundant fashion to rescue the system from possible data losses in case of failure. HDFS also makes applications available to parallel processing.
Advantages of Hadoop
- Hadoop framework allows the user to quickly write and test distributed systems. It is efficient, and it automatic distributes the data and work across the machines and in turn, utilizes the underlying parallelism of the CPU cores.
- Hadoop does not rely on hardware to provide fault-tolerance and high availability (FTHA), rather Hadoop library itself has been designed to detect and handle failures at the application layer.
- Servers can be added or removed from the cluster dynamically and Hadoop continues to operate without interruption.
- Another big advantage of Hadoop is that apart from being open source, it is compatible on all the platforms since it is Java based.
Features of Hadoop
- It is suitable for the distributed storage and processing.
- Hadoop provides a command interface to interact with HDFS.
- The built-in servers of namenode and datanode help users to easily check the status of cluster.
- Streaming access to file system data.
- HDFS provides file permissions and authentication.